Gemma 4を使ってみよう:ローカル環境への導入手順と活用ポイント

- 1. 導入
- 2. 前提条件
- 3. Jicoo(ジクー)について
導入
「APIの利用コストが気になって、社内データを使った検証が思い切りできない」「機密情報の壁があり、クラウドの商用LLMにデータを投げられない」。新しい技術を試したいのに身動きが取れず、現場は悲鳴を上げているはずです。
この記事を読むと、Googleが公開したオープンモデル「Gemma 4」を自社のローカル環境にインストールし、セキュアで自由なAI検証環境を構築できるようになります。
クラウドAPIに依存して利用枠やコストに怯える手動のワークフローから、自社専用のAIエンドポイントを立ち上げ、プロダクト主導でスピーディにプロトタイプを回せる環境への移行。それこそが、今エンジニア組織に求められている変化ではないでしょうか。
前提条件
本記事は、2026年4月10日時点の情報を基に解説します。対象読者は、自社プロジェクトでGemma 4をテスト導入したいエンジニアやデータサイエンティストです。
Gemma 4ファミリーには、用途に応じた複数のモデルサイズが存在します。ローカル環境で実行する場合、ハードウェア要件の確認が最初の関門となります。
- E2B / E4B(超小型・小型モデル): 量子化すれば1GB〜数GBのRAMで動作可能です。一般的なノートPCや、後述するスマートフォン、Raspberry Piなどでもオフライン実行が視野に入ります。
- **26B MoE / 31B Dense(中〜大規模モデル): 31BモデルをFP16精度でそのまま動かす場合、約62GBのVRAMを消費するため、80GBメモリを搭載したNVIDIA H100クラスのGPUが推奨されます。ただし、4bit量子化モデル(GGUF形式など)を利用すれば、VRAM消費を約18GB程度に抑えることができ、RTX3090(24GB)級の民生用GPUや、メモリ32GBを搭載したAppleシリコンのMacBookでも実行可能です。
実務的には、まずは手元のPCスペックに合わせてE4Bモデルから試し、日本語の出力品質を追求する段階で31Bの量子化モデルへステップアップするのが現実的なアプローチだと考えます。
手順(PC)
自前のPCやワークステーションにGemma 4を導入する手順は、大きく「環境準備」「モデル入手」「実行」の3ステップです。ここでは、Hugging FaceのTransformersライブラリを使用したPythonでの実行手順を解説します。
1. 実行フレームワークのインストール
まずはPython環境を用意し、必要なライブラリをインストールします。Gemma 4はリリース直後から主要なエコシステムに対応しているため、特別なビルドは不要です。
ターミナルを開き、以下のコマンドを実行します。
pip install -U transformers accelerate
2. モデルウェイトのダウンロード
次に、Hugging Faceからモデルをダウンロードします。初回実行時に自動でダウンロードさせることも可能ですが、数十GBの通信が発生するため、安定したネットワーク環境で行うことを推奨します。
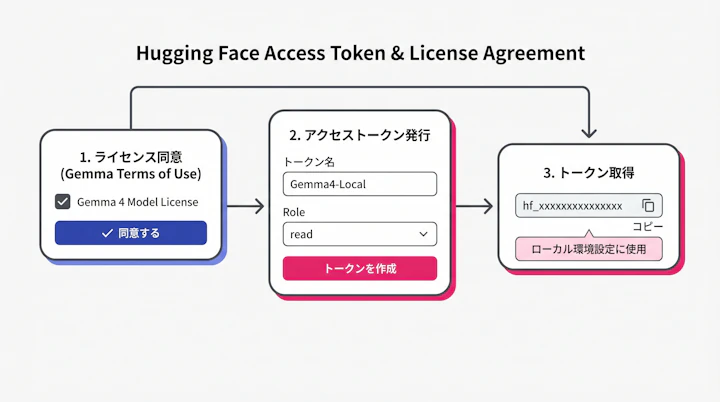
Hugging Faceのアカウントを作成し、Gemma 4のモデルページでライセンスへの同意(Gemma Terms of Use)を済ませておく必要があります。その後、アクセストークンを発行し、ローカル環境に設定してください。
3. ローカルでの推論実行
準備が整ったら、Pythonスクリプトからモデルをロードして推論を実行します。以下は、12B(またはE4B相当)のインストラクトモデルを読み込む最小限のコード例です。
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "google/gemma-4-12b-it" # 環境に合わせてモデルIDを変更
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype="auto"
)
prompt = "自社導入に向けたAIの活用アイデアを3つ提案してください。"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(</strong>inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
このコードを実行すると、モデルのロードが開始されます。メモリ消費量やロード時間を監視しながら、自社のハードウェアで安定稼働するかをテストしてみてください。
手順(スマホ)
Gemma 4の最小モデル(E2B)は、Androidスマートフォンなどのモバイル端末でも直接動かすことが可能です。PC環境との主な差分は以下の通りです。
- 実行環境の違い: PythonやTransformersではなく、Googleが提供する「AI Edge Gallery」や、モバイル向けの推論エンジン(MediaTekやQualcommのNPUに最適化された環境)を使用します。
- モデルの軽量化: スマホの限られたメモリ(RAM)で動かすため、INT8やINT4への量子化が必須となります。
現場感としては、スマホでのローカル実行は「ネットワークが遮断されたオフライン環境でも、デバイス内で完結するAIアシスタント」を構築する際に非常に強力な選択肢となります。
よくある失敗と対処
ローカル環境への導入時につまずきやすいポイントをまとめました。
Q. モデルのロード中にPCがフリーズしてしまう
A. メモリ(RAMまたはVRAM)の枯渇(OOM: Out of Memory)が原因です。特に31Bモデルをロードする際、スワップ領域を大量に消費してOS全体が重くなることがあります。まずはE4Bなどの軽量モデルに変更するか、GGUF形式の4bit量子化モデル(例:Q4_K_M)をOllamaなどのツール経由で実行してメモリ消費を抑えてください。
Q. 日本語の出力が不自然で、業務に使えそうにない A. パラメータ数の少ないモデル(E2BやE4B)は、英語の推論能力は高くても、複雑な日本語のニュアンスを捉えきれない場合があります。日本語用途であれば、可能な限り大きいモデル(31B)を使用する価値があります。ハードウェアの限界がある場合は、自社の日本語ドキュメントを用いてLoRAなどでファインチューニング(追加学習)を行うことを検討してください。
Q. 初回のダウンロードが途中で切れてしまう
A. モデルファイルは数十GBに及ぶため、ブラウザや単純なスクリプトでのダウンロードはタイムアウトしやすいです。Hugging Faceの公式CLIツール(huggingface-cli download)を使用すると、レジューム(再開)機能が働き、安全にダウンロードを完了できます。
運用を安定させるには
Gemma 4をローカルで動かせたとしても、それはスタートラインに過ぎません。「AIを動かすこと」自体が目的化してしまうと、結局は一部のエンジニアだけが触るおもちゃで終わってしまいます。
現場のチームが本当に求めているのは、日々の煩雑な業務から解放され、コア業務に集中できる心理的安全性の高い環境です。例えば、ローカルのGemma 4を使って商談の音声データをセキュアにテキスト化し、議事録やネクストアクションを自動抽出する仕組みを作ったとしましょう。しかし、抽出された「次回打ち合わせの調整」というタスクを、営業担当者が手作業でメールの往復をしていては、チームの疲弊は根本的には解決しません。
ここで重要なのは、AIの出力結果を実際の業務プロセスへとシームレスに繋ぐことです。抽出されたアクションアイテムを起点に、integrationを活用してJicooなどの日程調整ツールと連動させ、次回商談の予約リンクを自動で発行・送信する。このように、AIの推論結果を「具体的なアクションの自動化」にまで昇華させる体験こそが価値です。
手動でのコピペやツール間の反復移動をなくすことで、ヒューマンエラーは激減し、チームの雰囲気も劇的に改善するはずです。
まとめ
Gemma 4の登場により、APIコストやセキュリティの制約に縛られず、自社のローカル環境で高性能なaiを自由に検証できる時代が本格化しました。
次にやるべき1アクションは、「手元のPCで、OllamaやTransformersを使ってE4Bモデルをダウンロードし、簡単な対話テストを実行してみる」ことです。
まずは小さな成功体験を積み重ね、自社の業務課題を解決するためのプロダクト主導なAI活用へとステップアップしていきましょう。
Jicoo(ジクー)について
セールスや採用などのミーティングに関する業務を効率化し生産性を高める日程調整ツール。どの日程調整ツールが良いか選択にお困りの方は、まず無料で使い始めることができサービス連携や、必要に応じたデザインや通知のカスタマイズなどの機能が十分に備わっている日程調整ツールの導入がおすすめです。
チームで使える日程調整ツール「Jicoo」とは?